1、首先再导入基础包之后,先创建一组数据
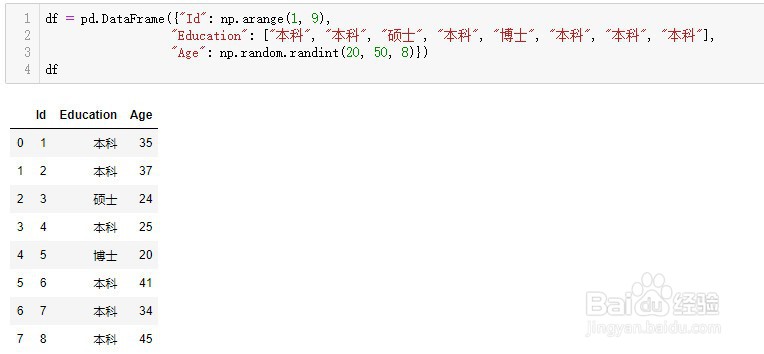
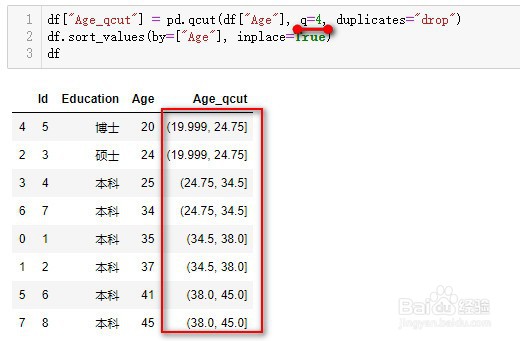
2、qcut是基于百分位来对连续数据分组,先来看一个例子
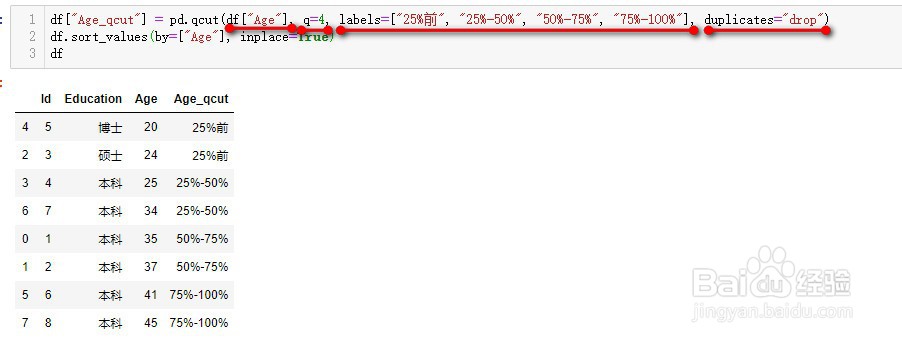
3、pd.qcut(x, q, labels, duplicates)
其中x为一维数组或Series,如本例中的Age

4、q:分位数的数量;
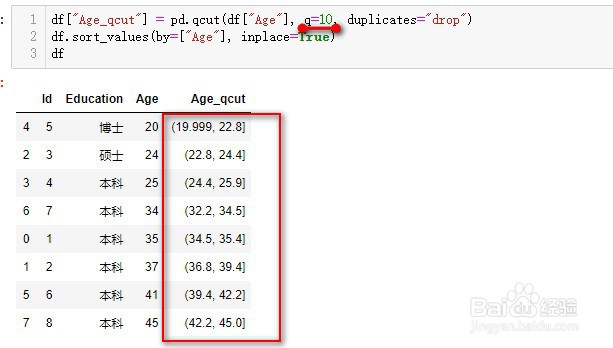
q=10代表切割为10个分位数区间,即百分位数,在10%、20%...位置切割
q=4代表按四分位数进行切割,即在25%、50%、75%处切割
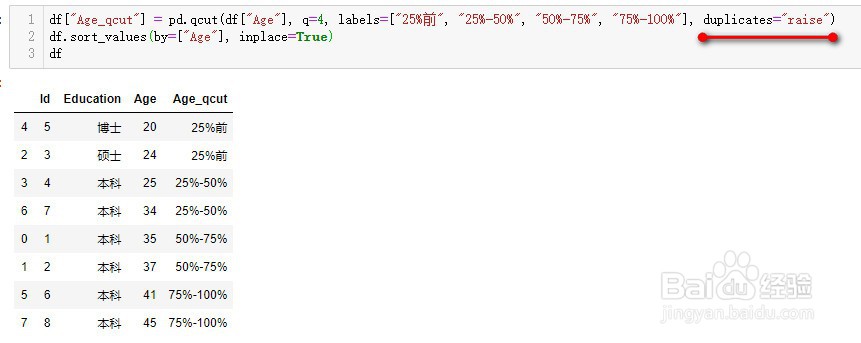
5、labels:为每个区间添加自定义标签

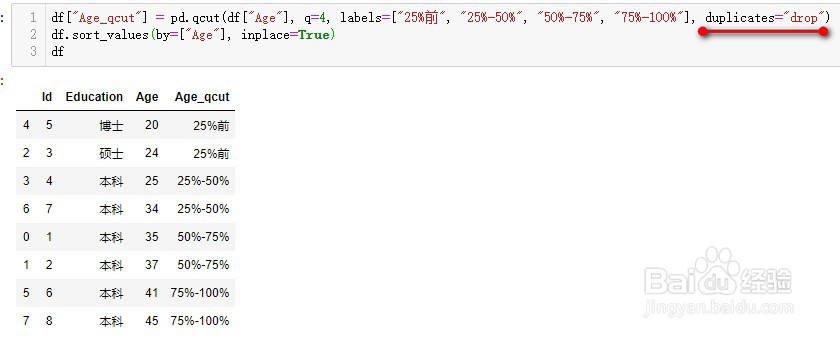
6、duplicates:用来决定当分组的边界值重复时,如何处理
raise:抛出错误(默认)
drop:删除重复值
(此次分割bin之间无重复值,故未抛出错误,当抛出错误时,改为drop即可)
7、剩余参数还有retbins、presion,可自行尝试
1、qcut在于多了一个q——分位数,意味着分割时总是按照全体数值均等分割成q份;
cut则指定好边界即可,并不会管每个区间记录数量是否大致相同